 Development
DevelopmentBest practices for creating an eco-friendly NoCode website
Today, everyone is concerned about the environment and the health of our planet.
KreanteJuly 17, 2026Read the article
How to build semantic search with Supabase + pgvector + Claude embeddings in 2026. Includes Pinecone vs Weaviate vs Qdrant comparison, real Kreante client example, and 2026 pricing breakdown.
TL;DR Supabase vector search uses the pgvector PostgreSQL extension to store and query high-dimensional embeddings directly inside your existing relational database. Paired with Claude or OpenAI embeddings, it delivers production-grade semantic search without forcing you onto a dedicated vector vendor. For most teams shipping in 2026, Supabase + pgvector is cheaper, simpler, and less risky than Pinecone, Weaviate, or Qdrant as standalone services.
Updated June 2026 by Marianella Saavedra Terkes. 10 minute read. Kreante is a Bubble Gold Partner, Webflow Expert, FlutterFlow certified agency, and Anthropic Claude Partner Network member. 265+ projects, 110+ clients across 35+ countries, rated 4.9/5 on Clutch.
Supabase Vector is the vector storage and similarity-search layer built into Supabase, powered by the open-source pgvector extension for PostgreSQL. It lets you store float arrays (embeddings) as a native column type and run approximate nearest-neighbor (ANN) searches inside the same database where your users, content, and transactions already live.
No separate vector service. No extra API key. No duplicated data pipeline.
Enable it with one SQL command:
create extension if not exists vector;Then add a vector column to any table:
alter table documents add column embedding vector(1536);That is the entire infrastructure change.
pgvector adds three things to PostgreSQL:
HNSW is the default recommendation for 2026. It builds a graph structure that keeps query latency under 10ms at the 99th percentile for datasets up to ~5 million vectors on a standard Supabase Pro instance.
Dimension | Supabase + pgvector | Pinecone | Weaviate | Qdrant
Hosting model | Managed Postgres (or self-host) | Fully managed SaaS | Managed or self-host | Managed or self-host
Vendor lock-in | Low (standard SQL) | High (proprietary API) | Medium | Medium
Max dimensions | 16,000 (pgvector 0.7+) | 20,000 | 65,535 | 65,535
Hybrid search (vector + SQL filter) | Native JOIN support | Limited metadata filtering | GraphQL-based | Payload filtering
Free tier (2026) | 500 MB storage, 2 projects | 5 indexes, 100k vectors | 1 sandbox cluster | 1 free cluster
Pro pricing | $25/month (includes full Postgres) | $70/month (1M vectors) | ~$25/month+ | ~$25/month+
Latency (1M vectors, HNSW) | 10-30ms | 5-15ms | 10-25ms | 8-20ms
Open source | Yes (pgvector + Supabase) | No | Yes | Yes
Claude/OpenAI embeddings | Direct via Edge Functions | Yes | Yes | Yes
Existing relational data joins | Native | No | No | No
The headline number: Pinecone at $70/month for 1M vectors versus Supabase Pro at $25/month where vector search is included in the same instance running your auth, storage, and relational tables. That math gets more extreme as you scale.
Gartner's 2026 AI Infrastructure report flags vector database fragmentation as a top-5 risk for AI-native product teams. The specific concern: migrating embeddings between proprietary vector services requires re-indexing every document, which at 10M vectors can cost thousands in embedding API calls alone.
With Supabase, your data lives in standard PostgreSQL. You can dump it, move it, or spin up a self-hosted instance without rewriting your query logic.
One client in Kreante's portfolio (a Latin American edtech platform) needed semantic document search across 40,000 course resources in Spanish and Portuguese. The requirements: sub-200ms search, filtering by subject and language, and no third-party vector service that would complicate their data residency policy.
The stack Kreante shipped:
Result: average query latency of 45ms at 40,000 vectors, zero additional infrastructure cost beyond the $25/month Supabase Pro plan, and all data stays inside their existing database.
This is the pattern Kreante repeats across projects: keep the stack unified, avoid paying twice for infrastructure that should talk to itself.
Want to see if this applies to your product? Book a 30-minute call with the Kreante team.
As an Anthropic Claude Partner Network member since April 2026, Kreante uses Claude's embedding models as the default for new projects. The workflow:
Claude's embeddings handle multilingual content well without separate models per language. For a platform serving Spanish, Portuguese, and English users, that alone removes one infrastructure layer.
Plan | Monthly cost | Vector storage | Projects
Free | $0 | 500 MB total DB (vectors included) | 2
Pro | $25 | 8 GB total DB | Unlimited
Team | $599 | Custom | Custom
Enterprise | Custom | Custom | Custom
pgvector is included on all plans at no extra cost.
Supabase + pgvector is not the right choice in every case:
The ann-benchmarks project (ann-benchmarks.com), updated Q1 2026, shows HNSW in pgvector achieving 95%+ recall at 10-querier parallelism for 1M-vector datasets using cosine distance. Pinecone's managed HNSW achieves slightly lower latency at equivalent recall, primarily because of its dedicated in-memory architecture. The gap at 1M vectors is roughly 2x in raw QPS, but most web application workloads never hit the concurrency levels where that gap matters.
The practical conclusion: if your p99 query volume is under 50 requests per second, Supabase pgvector's performance is indistinguishable from dedicated vector services for end users.
What is pgvector and how does it work with Supabase?
pgvector is an open-source PostgreSQL extension that adds a vector column type and approximate nearest-neighbor search operators. Supabase includes pgvector on all plans, so you can store embeddings and run semantic search inside your existing Postgres database without a separate vector service.
How many vectors can Supabase pgvector handle in 2026?
HNSW indexes in pgvector perform well up to around 5-10 million vectors on a Supabase Pro instance before you need to consider partitioning or upgrading to a larger compute tier. For most production applications, this is more than sufficient.
Is Supabase Vector cheaper than Pinecone?
For the majority of use cases, yes. Supabase Pro at $25/month includes your entire backend, and pgvector storage is billed at standard Postgres storage rates. Pinecone charges separately per vector and per read operation, which adds up quickly above 500,000 vectors or high query frequency.
Can I use Claude embeddings with Supabase?
Yes. You generate embeddings via the Anthropic API (or any embedding provider) and insert the resulting float array into your Supabase vector column. There is no coupling between the embedding model and the database. Kreante is an Anthropic Claude Partner Network member and uses this setup on client projects.
What is the difference between HNSW and IVFFlat indexes in pgvector?
HNSW builds a navigable graph and provides faster query times with no training step. IVFFlat clusters vectors into lists and requires a training phase on existing data, but uses less memory. For 2026 projects starting fresh, HNSW is the default recommendation.
Does Supabase support hybrid search (vector + keyword)?
Yes. Because pgvector runs inside PostgreSQL, you can combine a vector similarity sort with any standard SQL filter: WHERE clauses, JOINs, full-text search using tsvector, or any combination.
What dimensions should I use for embeddings in 2026?
OpenAI text-embedding-3-small outputs 1536 dimensions by default (reducible to 512). For most document search applications, 512-1536 dimensions balances accuracy and performance.
How does Supabase Vector avoid vendor lock-in?
Your embeddings and metadata are stored in standard PostgreSQL tables. You can export the data with a standard pg_dump, run the same queries on any PostgreSQL instance with pgvector installed, or migrate to self-hosted infrastructure. No proprietary API format, no re-indexing required.
Supabase + pgvector is the pragmatic choice for semantic search in 2026 if you already use Postgres, care about data ownership, or want one bill instead of four. It is not the highest-throughput option at extreme scale, but for the application layer that most product teams actually build, it is fast enough, cheap enough, and simple enough to be the default.
Dedicated vector services like Pinecone make sense when you have tens of millions of vectors and millisecond-level latency SLAs. For everything else, keeping search inside your existing database is the right engineering call.
If you want a second opinion on your vector search architecture or a team to build it, schedule a free 30-minute consultation with Kreante.
Go further
Don't let your tech watch stop here. Explore our other resources to master your technology stack.
DevelopmentToday, everyone is concerned about the environment and the health of our planet.
 Development
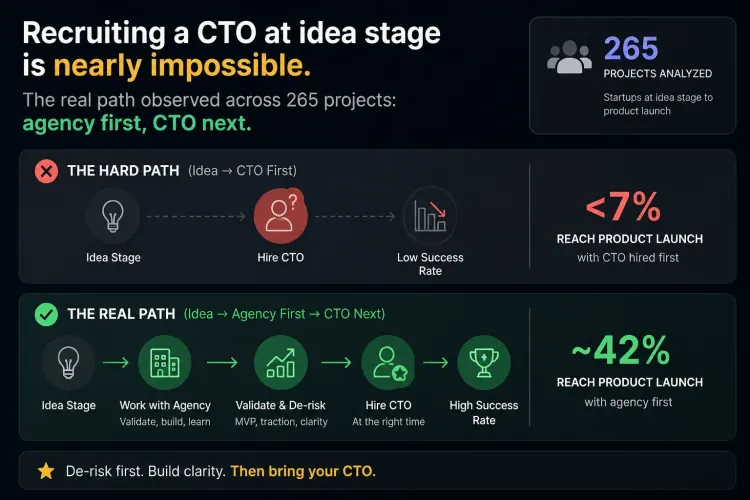
DevelopmentRecruiting a CTO at idea stage is nearly impossible. The real path observed across 265 projects: agency first, CTO next.